Using AI to Identify Authorship
A simple project using contrastive embeddings

Can language models be used to classify writers by style? The goal of this project is to learn zero-shot classification of authorial writing style using contrastive embeddings. For this we take an embedding derived from a language model and train a small adapter, we define a loss that optimizes the adapter such that texts with the same author are clustered close together regardless of content.
The methodology is inspired by recent work such as StyleDistance. Their approach includes the use of a large language model to create a synthetic dataset of paraphrases with controlled stylistic variations (e.g., formality) to train a style embedding model. We adapt this core idea by using synthetically generated texts by different authors as the basis for our contrastive pairs.
Methodology: Contrastive Learning Loss
To effectively disentangle the author’s style from the text’s content, we employ a contrastive learning framework using a triplet loss function. This approach teaches the model to focus on stylistic similarities rather than thematic ones.
1. Data Generation
The training data consists of a large set of short stories. These stories are systematically generated by a large language model, which is prompted to write on a wide variety of topics in the distinct style of several target authors. This creates a dataset where author and topic are controlled variables.
2. Triplet Construction
The core of our contrastive approach is the “triplet”—a set of three data points: an Anchor, a Positive, and a Negative. These are carefully selected to isolate the signal of style:
Anchor (A): A story written by a specific author on a specific topic.
Positive (P): A story written by the same author as the anchor, but on a different topic.
Negative (N): A story written by a different author, but on the same topic as either the anchor or the positive.
By training on these triplets, the model is forced to learn what makes one author’s writing consistent across different subjects, rather than simply learning to identify the subject itself.
3. Model and Embedding Space
First, each story is passed through a pre-trained text embedding model to obtain a high-dimensional content vector. A second, smaller neural network—the Style Encoder—is then trained. This model takes the preprocessed content embeddings as input and projects them into a low-dimensional, L2-normalized “style space”. The normalization ensures all style embeddings lie on the surface of a hypersphere, making cosine similarity a natural and effective distance metric. In our example, we just use 2 dimensions for the output vector.
4. Loss Function
The model is trained using a triplet margin loss based on cosine similarity. The objective is to ensure that, in the style space, the Anchor is closer to the Positive than it is to the Negative by at least a certain margin (α).
The loss for a single triplet (s_a, s_p, s_n being the style embeddings for A, P, and N) is formulated as:
cos(s_a, s_n)is the cosine similarity between the Anchor and the Negative.cos(s_a, s_p)is the cosine similarity between the Anchor and the Positive.
This is implemented in PyTorch as follows:
pos_sim = torch.sum(sa * sp, dim=1)neg_sim = torch.sum(sa * sn, dim=1)loss = torch.clamp(neg_sim - pos_sim + margin, min=0.0).mean()
This loss function penalizes the model whenever the (Anchor, Positive) pair is not sufficiently more similar than the (Anchor, Negative) pair, pushing the model to create distinct clusters for each author’s style.
Results
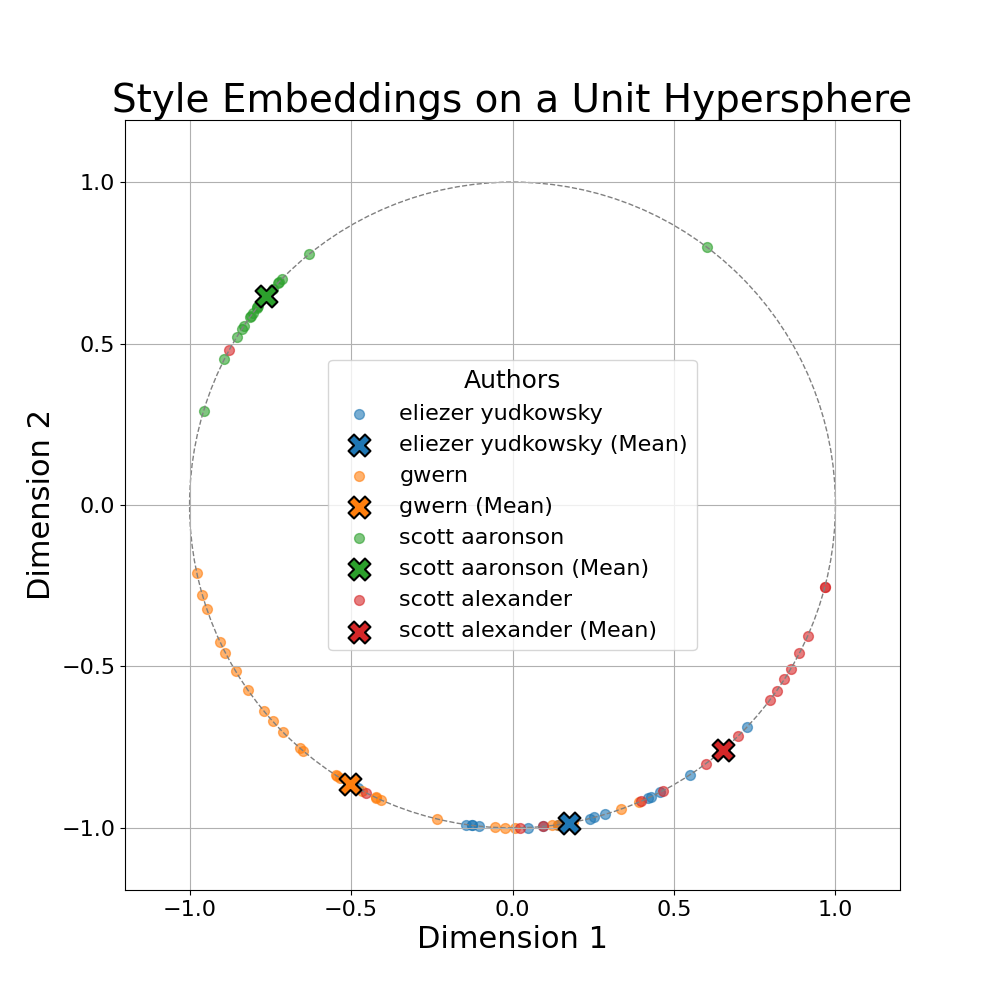
Check out the 2-D plot above, the plot clearly shows that the model is able to separate the authors to some extent.
Quantitative Results
To quantitatively evaluate the model, we use a Mean-Match Accuracy metric. First, we calculate the mean style vector for each author using the generated stories in the validation set. Then, for a given test story, we check if its style embedding is closer to the mean vector of its correct author than to any other author’s mean.
Validation Set (Generated Stories): The model achieves 77.50% accuracy on the held-out validation set of generated stories. This indicates that the learned style clusters are well-defined and internally consistent. However, this is synthetic data so it may just detect something about style of the LLM’s simulation of the author rather than the true style of the author.
Test Set (Real Stories): On a tiny test set of just four real-world writing samples (one per author), the model achieves 50.00% accuracy. A result from such a small sample is not statistically significant and should be viewed as more of a fun sanity check.