Run Local Speech-to-Text Transcription
Better Than SuperWhisper?

I wrote my own Speech-to-text transcription GUI.
Speech-to-text transcription has become essential for anyone who wants to reduce typing, avoid repetitive stress injuries, or quickly draft notes and projects. While cloud-based solutions exist, running transcription 100% locally gives you privacy, zero ongoing costs, and often better accuracy.
This post shows you how to set up your own local speech transcription system that works and is completely free.
What Others Are Saying About SuperWhisper
SuperWhisper has been getting attention in the AI alignment community. Neel Nanda and Lydia Nottingham have both recommended it as a productivity tool.
Why I Don’t Like SuperWhisper
I tried SuperWhisper recently and found it to be pretty bad, full of basic transcription mistakes. Here are my main issues:
Requires a $10/month subscription - Why should this cost money when all the technology is open source and powerful local models are freely available?
Cloud dependency - Even though SuperWhisper offers local processing, the default setup sends your voice to the cloud. If it runs locally, it’s basically a wrapper around open-source projects.
Mac only - No support for other operating systems.
The Simple CLI Solution
After trying various local options, I found the best solution uses whisper-ctranslate2. Installation is simple:
pip install whisper-ctranslate2
Then run it with optimized settings:
whisper-ctranslate2 \
--live_transcribe True \
--language en \
--model turbo \
--live_volume_threshold 0.02 \
--vad_filter True \
--vad_min_speech_duration_ms 1500 \
--vad_min_silence_duration_ms 900 \
--vad_max_speech_duration_s 30
Understanding the Parameters
Let me break down why each parameter matters:
--live_transcribe True- Enables real-time transcription as you speak--language en- Sets the language to English (change as needed)--model turbo- Uses OpenAI’s fastest Whisper model with excellent accuracy--live_volume_threshold 0.02- Sets sensitivity for detecting speech (lower = more sensitive)--vad_filter True- Enables Voice Activity Detection to filter out non-speech sounds--vad_min_speech_duration_ms 1500- Requires at least 1.5 seconds of speech before transcribing (reduces false starts)--vad_min_silence_duration_ms 900- Waits 900ms of silence before finalizing a segment (prevents cutting off words)--vad_max_speech_duration_s 30- Limits segments to 30 seconds maximum (improves processing speed)
Finding the right parameters took much longer than expected. The default settings are unusable.
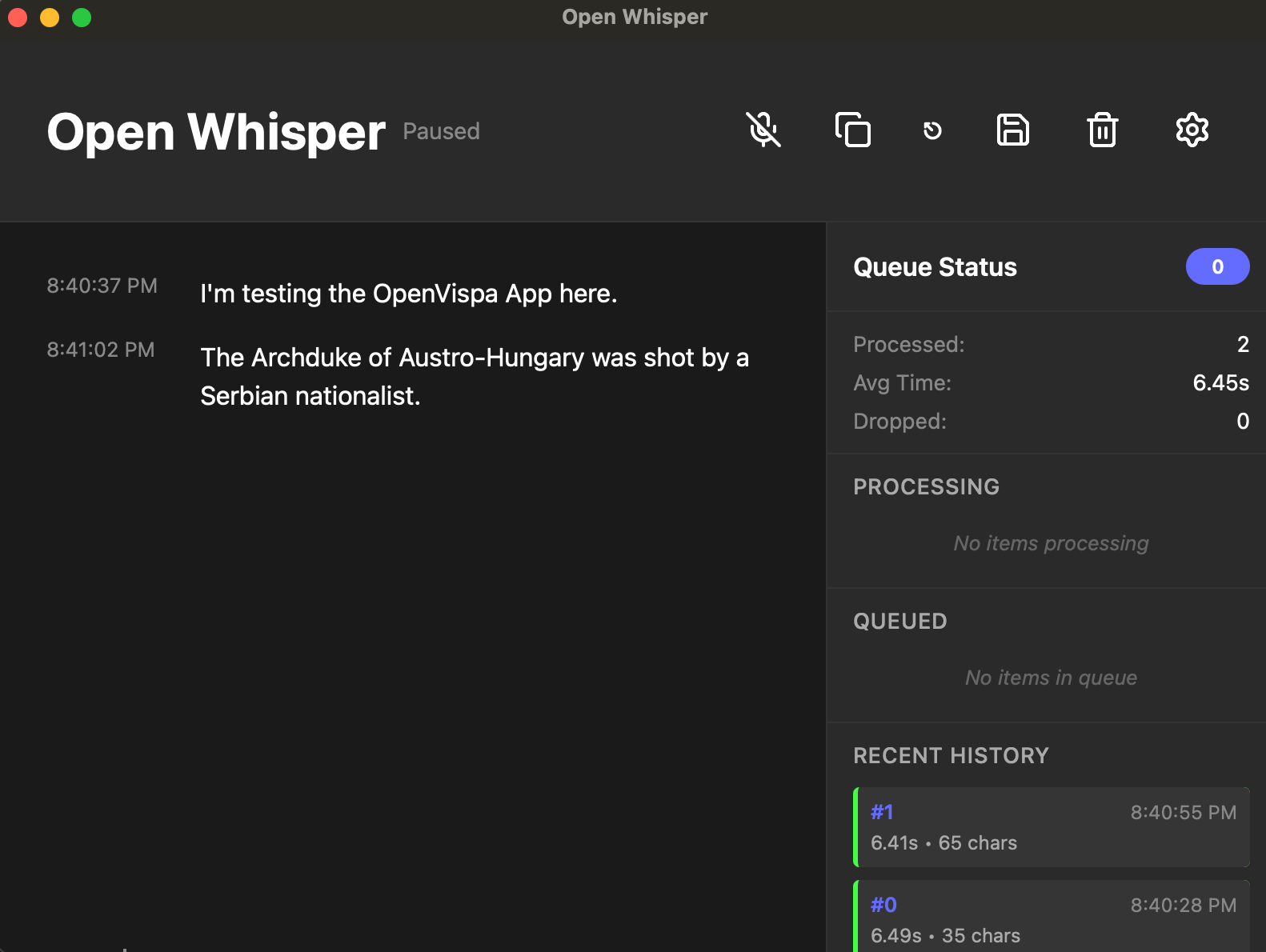
My Desktop App: Open Whisper
While the CLI works great, I wanted something more user-friendly. I built Open Whisper, a simple desktop app that wraps whisper-ctranslate2 with a clean interface.
Features:
100% local processing - No cloud, no subscriptions, complete privacy
Parallel transcription - Processes multiple audio segments simultaneously for better performance
File drag-and-drop - Easily transcribe existing audio files (MP3, WAV, M4A, OGG, FLAC)
Configurable - Adjust model, language, volume threshold, and silence detection
Hackable - Add your own features with tools like Claude Code or by yourself
Current Limitations:
No global shortcuts yet - Can’t paste transcripts everywhere with a hotkey (working on it)
Try It Yourself
The code is open source and available on GitHub: github.com/dalasnoin/open_whisper
To run it:
git clone https://github.com/dalasnoin/open_whispercd open_whisperpip install uvuv syncbash ./start_desktop.sh
What You Can Use This For
Live transcription:
Taking notes during meetings or research
Creating first drafts of blog posts, essays, or projects
Reducing typing to avoid repetitive stress injuries (RSI)
Dictating code comments or documentation
File transcription:
Transcribing existing audio recordings
Converting interview recordings to text
Processing podcast episodes or lectures
Conclusion
You don’t need a $10/month subscription for speech-to-text. The open-source options are better, faster, and completely private. Start with the CLI command above, or try Open Whisper if you want a nicer interface.
The transcription quality is excellent, it runs entirely on your machine, and you have full control over your data. Plus, you can continue vibe coding in new features as you need them.
excited to try this tomorrow!